Launch GPU-accelerated environments in a click, with pay-as-you-go pricing and no reserved capacity to manage.
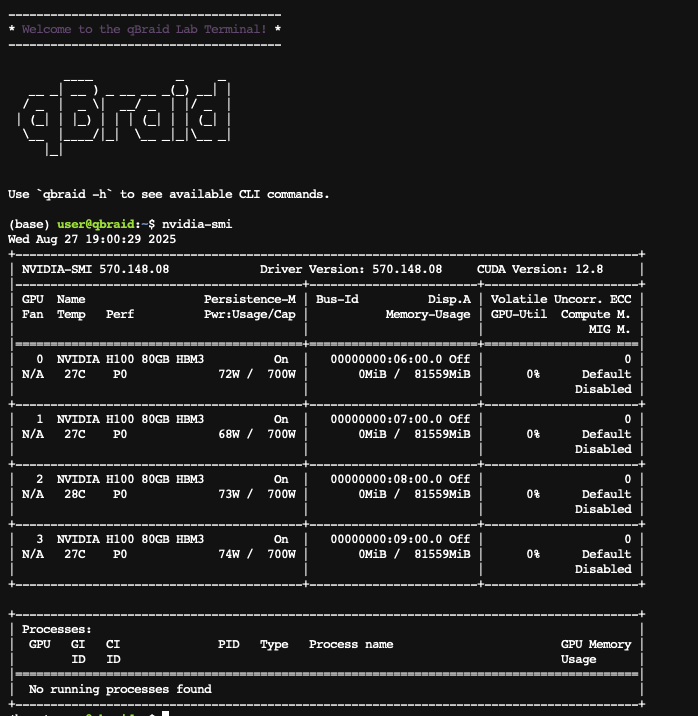
We're excited to share a major expansion of on-demand GPU computing on qBraid Lab. You can now spin up more than 20 GPU instance configurations spanning NVIDIA's Blackwell, Hopper, Ampere, and Ada Lovelace architectures, all directly from the qBraid dashboard. Pick the hardware you need, click Launch, and get to work. No reserved capacity, no separate cloud account, and no infrastructure to maintain.
What's in the fleet
The expanded lineup covers single-GPU and multi-GPU configurations across a wide range of NVIDIA hardware:
- NVIDIA B200 (Blackwell)
- NVIDIA H200 and H100 (Hopper)
- NVIDIA GH200 (Grace Hopper)
- NVIDIA A100 (Ampere)
- NVIDIA L4, L40S, RTX 4090, RTX 5090, RTX 6000 Ada
On-demand CPU instances are also available up to 64 vCPU and 256 GB of RAM. And because you can run up to five instances at once, it's easy to run parallel experiments, compare hardware side by side, or keep a development environment going right alongside a production job.
How it works
Pick an instance from the qBraid account dashboard and click Launch. Real-time availability indicators show which instances have capacity before you launch, and pricing is displayed transparently in credits per minute, so there are no surprises.
Once your instance is running, open it in JupyterLab, VS Code, or an integrated terminal, all from the browser. Prefer your local setup? You can SSH into any instance with the qBraid CLI and fold on-demand GPUs straight into the workflow you already use.
Why we built this
Quantum research leans on GPUs more every year, from tensor network simulation and variational algorithms to quantum machine learning, neural-network error-correction decoding, and automated qubit calibration. That reliance keeps deepening – NVIDIA's recent release of Ising, its first family of open AI models for quantum calibration and error-correction decoding, works hand in hand with the CUDA-Q programming model and underscores just how central GPUs have become to the field. The same is true for teams working on quantum-inspired and AI methods.
Access to high-end GPUs used to mean wrestling with cloud consoles, juggling credentials, and standing up infrastructure before you could run a single line of code. qBraid removes that friction, and makes GPUs accessible to everyone.
"Our users want to focus on their research, not on managing infrastructure," said Ryan Hill, CTO of qBraid. "They should be able to pick the hardware they need and start working. That's what this expansion delivers: the broadest GPU selection we've ever offered, with zero infrastructure overhead."
Pricing and availability
On-demand GPU instances are live now on qBraid Lab with pay-as-you-go, credit-based pricing. You can find full details on the qBraid pricing page, and you can get started today at account.qbraid.com.
Build with us
Building GPU-accelerated quantum or AI workflows? The qBraid-SDK is open source and integrates with the frameworks that power them, including CUDA-Q. We'd love to see what you build. Explore the qBraid-SDK and join our developer community on GitHub: github.com/qBraid/qBraid.
Want to try CUDA-Q? It comes pre-configured on qBraid Lab. Select the environment, open a notebook, and start writing CUDA-Q kernels with no installation or setup required.






.png)














-min.jpeg)

















.png)










